분할 정복 (재귀, 시간복잡도, 점화식)
알고리즘 시리즈의 첫 글은 분할 정복(Divide and Conquer)이다. 이름이 거창해 보이지만 발상은 단순하다. 큰 문제를 같은 형태의 작은 문제 두세 개로 쪼개고, 작은 문제들의 답을 합쳐 원래 문제의 답을 만드는 전략이다. 이 단순한 아이디어 위에 병합 정렬·퀵 정렬·이진 탐색·고속 푸리에 변환·행렬 곱셈 같은 거의 모든 고급 알고리즘이 서 있으며, 같은 사고 틀이 그래픽스의 KD-Tree·DB의 B-Tree·MapReduce의 분산 처리까지 확장된다. 본 글은 분할 정복의 정의·시간복잡도 분석·마스터 정리·실전 예시를 세심하게 정리한다(출처: CLRS — Introduction to Algorithms). 제가 학교 알고리즘 수업에서 처음 같은 정렬 문제를 버블 정렬과 병합 정렬로 시간 측정해 본 후 1000배 차이가 나는 모습을 직접 봤을 때 "분할 정복은 단순한 기법이 아니라 다른 시간 차원의 알고리즘 패밀리"라는 인상을 손끝으로 받아들였다.
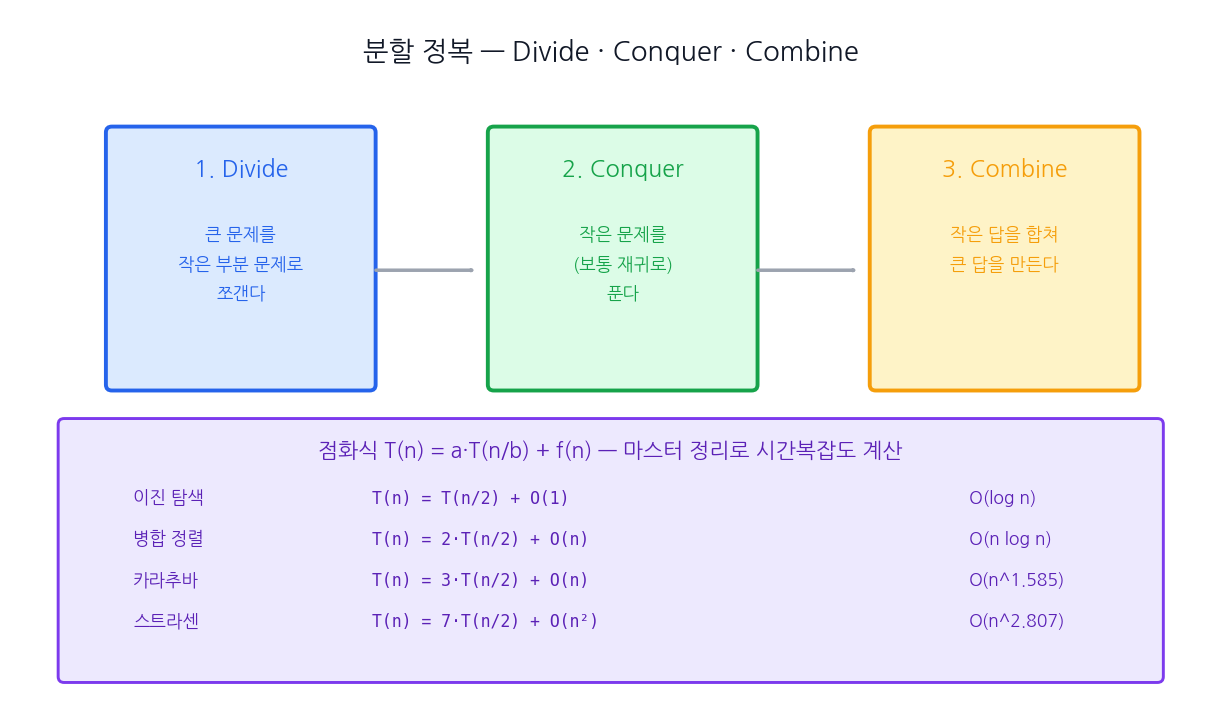
분할 정복의 3단계 — Divide · Conquer · Combine
분할 정복 알고리즘은 어느 영역의 문제든 다음 세 단계의 동일한 골격을 따른다.
- 분할(Divide) — 큰 문제를 같은 형태의 작은 문제 두세 개로 쪼갠다.
- 정복(Conquer) — 작은 문제들을 (보통 재귀로) 푼다. 충분히 작아지면 직접 푼다.
- 결합(Combine) — 작은 답을 합쳐 큰 답을 만든다.
여기서 결합 단계의 비용이 알고리즘 전체의 시간복잡도를 결정짓는 핵심 변수다. 예를 들어 병합 정렬은 분할 비용이 O(1)이지만 결합(병합)에 O(n)이 들어 전체 O(n log n)이 되고, 이진 탐색은 분할도 결합도 O(1)이라 전체 O(log n)이 된다. 솔직히 제 경험상 학교 시험에서 두 알고리즘의 시간복잡도 차이를 묻는 문제는 거의 모두 "결합 단계가 무엇인가"라는 한 질문으로 환원된다는 점을 깨달은 후 답안 작성이 단순해졌다.
# 분할 정복 — 이진 탐색 (가장 단순한 분할 정복)
def binary_search(arr, target, lo, hi):
if lo > hi: return -1
mid = (lo + hi) // 2
if arr[mid] == target: return mid
elif arr[mid] < target:
return binary_search(arr, target, mid + 1, hi) # 우측 반만
else:
return binary_search(arr, target, lo, mid - 1) # 좌측 반만
# 분할 정복 — 병합 정렬
def merge_sort(a):
if len(a) <= 1: return a
mid = len(a) // 2
left = merge_sort(a[:mid]) # 분할 + 정복
right = merge_sort(a[mid:])
return merge(left, right) # 결합
def merge(l, r):
out, i, j = [], 0, 0
while i < len(l) and j < len(r):
if l[i] <= r[j]: out.append(l[i]); i += 1
else: out.append(r[j]); j += 1
out.extend(l[i:]); out.extend(r[j:])
return out시간복잡도와 점화식 — 마스터 정리
분할 정복 알고리즘의 시간복잡도는 거의 항상 다음 형태의 점화식(recurrence relation)으로 표현된다.
T(n) = a · T(n / b) + f(n)여기서 a는 부분 문제 개수, b는 한 단계마다 줄어드는 비율, f(n)은 분할과 결합에 드는 비용이다. 이 점화식을 풀어 닫힌 형태의 시간복잡도를 얻는 가장 자주 쓰이는 도구가 마스터 정리(Master Theorem)이다(출처: 위키백과 — Master theorem).
| 케이스 | 조건 | 결과 |
|---|---|---|
| 1 | f(n) = O(n^c), c < log_b(a) | T(n) = Θ(n^(log_b a)) |
| 2 | f(n) = Θ(n^c · log^k n), c = log_b(a) | T(n) = Θ(n^c · log^(k+1) n) |
| 3 | f(n) = Ω(n^c), c > log_b(a) | T(n) = Θ(f(n)) |
여기서 점화식이란 같은 함수가 자기 자신을 인자가 작아진 형태로 호출하는 등식을 가리키며, 분할 정복 알고리즘의 시간복잡도를 정확히 표현하는 표준 도구이다. 자주 등장하는 알고리즘들을 표로 정리하면 다음과 같다.
| 알고리즘 | 점화식 | 시간복잡도 |
|---|---|---|
| 이진 탐색 | T(n) = T(n/2) + O(1) | O(log n) |
| 병합 정렬 | T(n) = 2·T(n/2) + O(n) | O(n log n) |
| 퀵 정렬 (평균) | T(n) = 2·T(n/2) + O(n) | O(n log n) |
| 퀵 정렬 (최악) | T(n) = T(n-1) + O(n) | O(n²) |
| 카라추바 곱셈 | T(n) = 3·T(n/2) + O(n) | O(n^1.585) |
| 스트라센 행렬 곱 | T(n) = 7·T(n/2) + O(n²) | O(n^2.807) |
카라추바(Karatsuba) 곱셈과 스트라센(Strassen) 행렬 곱이 인상적인 이유는 부분 문제 수를 한 개 줄이는 것만으로 시간복잡도가 한 단계 내려가는 현상을 보여 주기 때문이다. 두 알고리즘 모두 분할의 영리한 재구성으로 O(n²)·O(n³)를 깨뜨린 고전 사례이며, 같은 원리가 FFT(O(n log n) 다항식 곱셈)까지 이어진다. 솔직히 이건 예상 밖이었는데, 학교에서 처음 마스터 정리로 카라추바의 1.585를 손으로 계산해 본 후로는 "분할 한 줄을 바꾸는 게 시간 차원을 바꾼다"는 사실을 머리가 아니라 손가락으로 받아들였다.
실전 예시 — 최대 부분 배열과 가장 가까운 두 점
마지막으로 분할 정복의 두 가지 고전 응용을 손으로 따라가 보자.
최대 부분 배열 합(Maximum Subarray Sum): 배열에서 연속 부분의 합이 최대가 되는 구간을 찾는 문제. 단순 풀이는 O(n²)이지만 분할 정복으로 O(n log n)에 풀 수 있다. 핵심 아이디어는 "최대 부분 배열은 좌측 절반에 있거나, 우측 절반에 있거나, 가운데를 가로지른다"는 세 케이스의 분기다. (카데인 알고리즘으로는 O(n)에 풀 수 있지만, 분할 정복 사고 훈련용으로 자주 출제된다.)
def max_subarray(a, lo, hi):
if lo == hi: return a[lo]
mid = (lo + hi) // 2
left_max = max_subarray(a, lo, mid)
right_max = max_subarray(a, mid + 1, hi)
# 가운데를 가로지르는 최대 합
cross = 0; cur = 0
left_part = float('-inf')
for i in range(mid, lo - 1, -1):
cur += a[i]; left_part = max(left_part, cur)
cur = 0; right_part = float('-inf')
for i in range(mid + 1, hi + 1):
cur += a[i]; right_part = max(right_part, cur)
cross = left_part + right_part
return max(left_max, right_max, cross)가장 가까운 두 점(Closest Pair of Points): 2차원 평면의 n개 점 중 가장 가까운 두 점을 찾는 문제. 모든 쌍을 비교하면 O(n²)이지만, 점들을 x축으로 정렬한 뒤 좌·우로 분할해 재귀로 풀고 중앙선 주변의 좁은 띠만 검사하는 분할 정복으로 O(n log n)에 끝난다. 컴퓨터 그래픽스·게임·로보틱스의 충돌 감지에 응용되는 고전이며, 분할 정복이 단순한 정렬·탐색을 넘어 기하 문제까지 다룰 수 있음을 보여 준다.
분할 정복으로 푸는 문제의 공통 패턴은 다음 세 가지로 압축된다. 첫째, 재귀 가능한 자기 유사성이 있어야 한다(작은 문제가 큰 문제와 같은 모양). 둘째, 결합 단계의 비용이 분할·정복 단계와 균형을 이뤄야 한다. 셋째, 종료 조건(base case)이 명확해야 한다. 이 세 가지를 의식하고 새 문제를 마주하면, "이 문제는 분할 정복이 어울리는가, 아닌가"를 빠르게 판단할 수 있다. 마지막으로 시험 답안에서 자주 쓰이는 정형 표현을 정리하면, "분할 정복은 큰 문제를 같은 형태의 작은 문제로 쪼개고(Divide), 작은 문제들을 재귀로 풀고(Conquer), 답을 합쳐 큰 답을 만드는(Combine) 알고리즘 설계 패러다임이다. 시간복잡도는 점화식 T(n) = a·T(n/b) + f(n)으로 표현되며 마스터 정리로 풀 수 있다"는 두 문장이 표준 답안 표현으로 통한다.
메타 디스크립션: 분할 정복 알고리즘 설계 패러다임의 3단계(Divide·Conquer·Combine), 점화식과 마스터 정리, 그리고 이진 탐색·병합 정렬·최대 부분 배열·가장 가까운 두 점 같은 고전 응용까지 알고리즘 입문자 관점에서 세심하게 정리합니다.